摘要:
论文论述了利用机器学习的相关技术,整合监督相关数据,提取在押人员和历史人员的相关特征和风险评估表特征,利用大数据、机器学习、深度学习技术,研发和建设了一套监所人员风险评估算法模型。
大数据是一种手段,并不能无所不包、无所不用。研究并利用大数据技术的根本目的在于用好数据,通过挖掘海量数据中的隐藏价值,实现数据赋能业务。大数据建模本质上是一个机器学习的过程,机器学习是一门研究怎样使用数据思维解决问题的学科,它的原理和人类思维非常相似,人类是基于经验对规律进行总结和归纳,而机器(计算机)则是基于数据(即经验的外在体现),利用算法来总结规律,并作出预测。
当前,信息技术、网络技术已经进入了各行各业,现代社会治安隐患、新型犯罪活动等也更加智能化、隐蔽化,甚至出现了许多高科技犯罪手法,被动搜集信息的公安警务工作模式已经跟不上社会发展的脚步,而将大数据智能化技术深入应用,可以有效提高公安机关的打击犯罪能力、保障社会安全的能力!
本篇论文刊登于《警察技术》2022年第1期
本文由杭州中奥科技有限公司(北京研究院、数据智能部)、公安部第一研究所联合编写。
关键词:风险评估预警模型、机器学习、半监督、支持向量机、K近邻、随机森林
一、背景
我国目前的监狱人员管理现状,多数还停留在以狱警巡查加摄像机监视报警的阶段,人工作业仍占绝大比重,信息化程度比较低。
为提高监管风险识别水平,我们可以利用机器学习的相关技术,整合监管方面的相关数据,提取服刑人员相关特征和风险评估表,利用大数据、数据库处理技术、计算机软件技术、地理信息系统技术、互联网技术等多学科能力,研发和建设了这套狱所人员的风险评估算法模型,实现监所管理信息化,检索的智能化。
二、模型构建相关技术
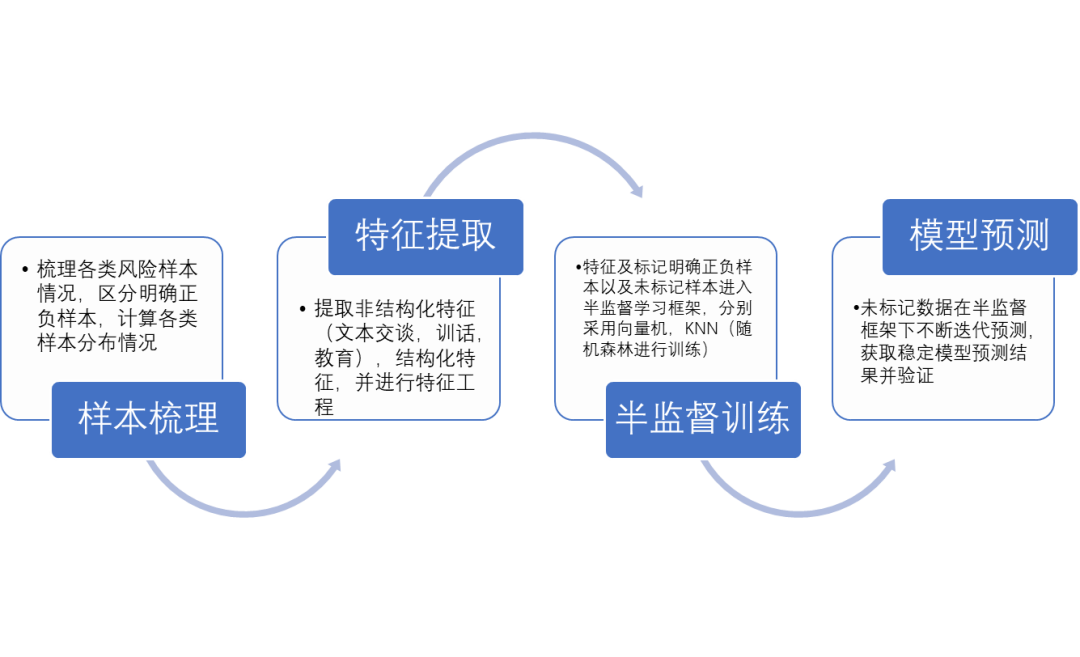
2.1 模型整体框架
在传统机器学习行业中,无标签的数据易于获取,而有标签的数据收集起来通常很困难,标注也耗时和耗力。在这种情况下,半监督学习更适用于现实世界中的应用。
在分辨监所人员风险训练样本时,我们只能通过以往人员犯事记录进行风险标记,对于那些没有明显表征,但潜在存在风险的人员我们缺无法完全标记为无风险白样本。
本模型是一种基于半监督学习框架的特征向量学习预测模型方法
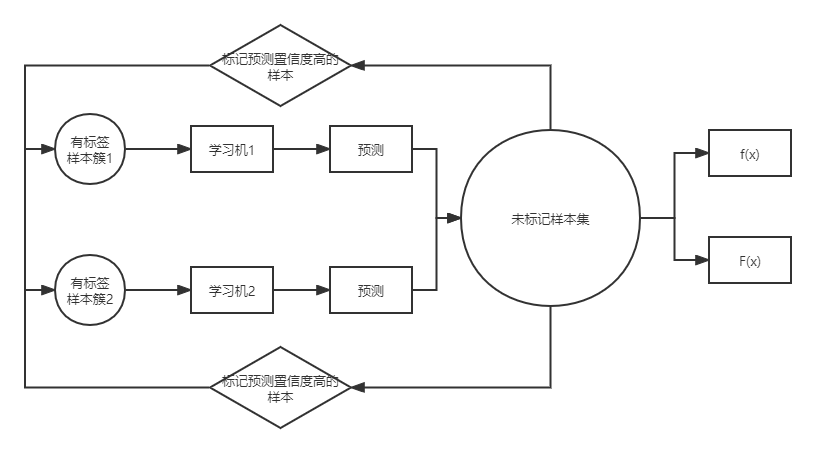
图2 半监督学习架构图
2.2 模型特征提取
采用模型的特征在已知结构化特征提取的基础上增加非结构化特征提取。结构化特征提取在行业内常用成熟。
一般简单的非结构化特征提取采用正则+规则的形式,往往用在身份证号,生日,手机号等规则的实体提取场景采用,但在本场景中,监所数据中非结构化特征大量存在于谈话记录,教育记录,历史档案等复杂文本当中,提取的体征也较身份证号这类实体复杂。
因此我们采用基于深度学习的命名实体识别技术BERT+CRF(神经网络进行提取。BERT使用Transformer作为获取文本表征的手段(主要依赖了多头的self-attention机制, 见图3), 能够获取比BiLstm更深层次的语言表征。
基于谷歌预训练的中文BERT模型, 结合我们的命名实体识别任务(针对特定场景的标注和训练), 在保证模型有较强泛能力的同时, 提升特定场景下的模型准确率。使用BERT提取文本向量特征后,与结构化特征一起构建人员特征宽表待进入半监督模型训练。
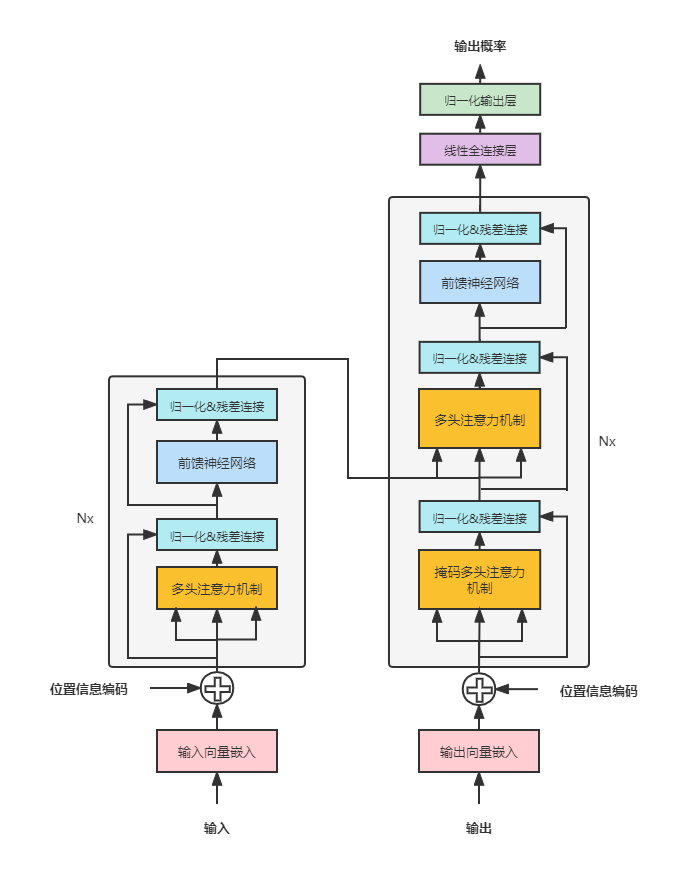
图3 BERT Transform框架
三、数据的分析及处理
3.1 数据特征筛选
参考数据库表和表内数据,提取健康、闹监、心理等六个模型的关键属性,摘取模型训练所需的特征维度。
在押危险人员具备区别于普通在押人员的一些特点和活动规律。通过针对所需要分析的目标人群的背景信息、案件信息、奖惩信息、就医信息、健康情况、违纪违规等数据加上人员在押生活中记录的如谈话记录、教育记录,案件案情,客观评价等非结构化文本类信息,提取出多维度的特征标签形成特征宽表,通过模型训练结合业务角度从在押人员中挖掘出潜在的高风险人员。
3.2 数据预处理
针对特征进行归一化处理,z-score归一化转化为0-1之间的数值,使得各个特征在同一度量维度下,从而使它们之间的权重更好处理。此外,采用利用均值和标准差对数值进行归一化,针对年龄、同行次数等连续型特征进行离散化,将其等频离散化/等区间离散化处理,降低算法对于分布假设的依赖性。
针对每个数值型特征,结合特征的分布及与目标分类的分布情况,对于特征进行数学变化,比如次方,三次方,取自然对数等数学变换。
3.3 特征向量数据平滑处理
进行特征向量提取和表示时,并不是每个特征值在每个维度都有数值,经常该字段为空值或者缺失,当词汇在某个维度未出现时,记录该特征点时用0来表示,但是该特征对应的特征向量就会出现一个断点,这对模型训练和结果分析时造成了很大困难,需要对特征进行修正,以达到能符合后续处理的需要。本文采用滑动平均值来处理数值断点问题。
3.4 特征向量人工标注
于模型训练的特征数据需要人工进行标注,数据有了标签,机器才可以根据带有标签的数据进行模型训练,数据标注标准采用是否有风险进行标注,即对数据的多个维度进行人工综合分析,并判断该犯人是否有健康、闹监、心理等六个方向的风险,标注人员为具有多年看守所工作经验的预警,标注人员只需要根据犯人的特征数据表中的信息,在上述的健康、闹监、心理等六个方向上打上是或否的标记,是表示该犯人具有该方向的风险,而否表示该犯人无该方向的风险。
四、半监督学习模型训练
4.1 不同类别基分类器模型选择
在进行健康、闹监、心理等六个模型训练时,由于特征数据的维度和疏密程度不同,所以采用的机器学习框架不同。根据数据和风险评估的最终效果,选取了K近邻算法、支持向量机模型和随机森林模型。
4.2 实验结果与分析
在对健康、闹监、心理等6个模型进行五轮交叉验证模型训练后,利用训练好的模型对测试数据进行预测,计算得到每个模型的准确率(ACC)和召回率(REC)。综合评估,六个模型平均的准确率和召回率达到80%以上,当在训练数据积累较多时,特征维度较为丰富时,使用非距离计算的树形模型具有较好的泛化性。
如今信息化智能化已在遍地开花,机器学习技术已日趋成熟,已在金融、军事、政府、公安等各个领域应用广泛。看守所和监狱这类监管的行业更加需要信息化注入新的力量,以便于更好的为社会主义建设服务。而人工智能在监管领域落地,更进一步说明信息化建设迫在眉睫。因此,机器学习和人工智能在监狱行业的落地具有重要意义。
本文提出了一种基于半监督学习的监所狱所风险人员评估的计算方法,也总结了具体的远程,针对不同种类特征数据不同机器学习训练模型的优劣。对于在模型训练过程中人工标注数据较少,特征向量中缺失值较多的情况,某些人员的特征性质可能并没有在数据特征层面取得较好的体现。在将来的研究中,需要更加细致的统计人员的相关特征,这样才能更加细致的体现风险评估的准确性。
本篇论文刊登于《警察技术》2022年第1期
全国统一客服热线


 浙公网安备 33010502007057号
浙公网安备 33010502007057号
